
개발을 진행하면서 카프카 클러스터를 외부에 노출시켜야 하는 경우, 같은 VPC 내부에서 작업하지 않고 개발용 클러스터를 구축해야 하는 경우가 있었다.
기본적으로 카프카 클러스터는 VPC 내부에서 Private하게 사용되는 것이 보안상 올바르다. 클러스터에 누구나 접근 가능하다는 점이 보안상 위험한 부분이다.
따라서 AWS MSK 또한 VPC 외부에서의 접근을 원칙적으로 막고있다.
하지만 개발용 환경을 분리시켜놓고, TDD - 통합 테스트 과정에 있어서 카프카 클러스터 접근이 필수적으로 요구되고, 이를 위해 코드를 분리할 필요없이 통합 테스트를 수행할 수 있어서 데이터베이스와 구성 환경만을 잘 구분짓는다면 개발 환경과 프로덕트 환경간의 간극을 확실히 줄일 수 있다고 생각해 클러스터를 노출시키기로 결정했다.
Docker compose
카프카 클러스터를 K8S의 Deployment로 관리해도 되겠지만 개발환경이고 간단하게 배포하기 위해 Docker Compose로 구성했다.
Cluster.yml
version: "3.0"
services:
zk1:
image: zookeeper
restart: always
hostname: zk1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
volumes:
- "~/zk-cluster/zk1/data:/data"
zk2:
image: zookeeper
restart: always
hostname: zk2
ports:
- "2182:2181"
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
volumes:
- "~/zk-cluster/zk2/data:/data"
zk3:
image: zookeeper
restart: always
hostname: zk3
ports:
- "2183:2181"
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
volumes:
- "~/zk-cluster/zk3/data:/data"
zoo-navi:
image: elkozmon/zoonavigator
ports:
- 9000:9000
environment:
HTTP_PORT: 9000
kafka1:
image: confluentinc/cp-kafka
depends_on:
- zk1
- zk2
- zk3
restart: on-failure
ports:
- 9091:9091
environment:
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<로컬 머신 IP>:9091
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9091
- KAFKA_ZOOKEEPER_CONNECT=zk1:2181,zk2:2181,zk3:2181
- KAFKA_BROKER_ID=1
- BOOTSTRAP_SERVERS=kafka1:9091,kafka2:9092,kafka3:9093
kafka2:
image: confluentinc/cp-kafka
depends_on:
- zk1
- zk2
- zk3
restart: on-failure
ports:
- 9092:9092
environment:
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<로컬 머신 IP>:9092
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_ZOOKEEPER_CONNECT=zk1:2181,zk2:2181,zk3:2181
- KAFKA_BROKER_ID=2
- BOOTSTRAP_SERVERS=kafka1:9091,kafka2:9092,kafka3:9093
kafka3:
image: confluentinc/cp-kafka
depends_on:
- zk1
- zk2
- zk3
restart: on-failure
ports:
- 9093:9093
environment:
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<로컬 머신 IP>:9093
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093
- KAFKA_ZOOKEEPER_CONNECT=zk1:2181,zk2:2181,zk3:2181
- KAFKA_BROKER_ID=3
- BOOTSTRAP_SERVERS=kafka1:9091,kafka2:9092,kafka3:9093
위 코드는 3개의 Zookeeper와 3개의 카프카 브로커로 구성된 클러스터를 보여준다.
ZooKeeper 설정:
각 ZooKeeper 서버는 독립된 호스트 이름(zk1, zk2, zk3)을 가지며, 각각 다른 포트(2181, 2182, 2183)를 통해 접근할 수 있다.
- ZOO_MY_ID : 각 ZooKeeper 인스턴스에 대한 고유 ID를 설정한다. 클러스터에서 각 인스턴스를 식별하는 데 사용된다.
- ZOO_SERVERS : 클러스터 구성을 정의하며, 각 서버의 ID와 통신을 위한 포트(2888, 3888) 및 클라이언트 요청을 위한 포트(2181)를 포함한다.
- volumes : 각 ZooKeeper 인스턴스의 데이터를 호스트 시스템의 디렉토리에 저장하여 데이터의 영속성을 보장한다.
Kafka 설정:
각 Kafka 브로커는 서로 다른 포트(9091, 9092, 9093)를 통해 접근 가능하다.
- depends_on : Kafka 서비스가 ZooKeeper 클러스터에 의존하며, ZooKeeper 서비스가 구동된 후에 Kafka 서비스가 시작되도록 설정한다.
- KAFKA_ADVERTISED_LISTENERS : Kafka 브로커가 외부에서 접근 가능한 주소를 설정한다. EC2 의 퍼블릭 IP를 넣어주자.
- KAFKA_LISTENERS : Kafka 브로커가 내부적으로 사용하는 네트워크 주소를 설정한다.
- KAFKA_ZOOKEEPER_CONNECT : Kafka 브로커가 ZooKeeper 서버와 연결하기 위한 설정이다.
- KAFKA_BROKER_ID : 각 Kafka 브로커의 고유 ID를 설정한다.
- BOOTSTRAP_SERVERS : 클라이언트가 최초로 연결할 Kafka 브로커의 목록을 제공한다.
Kafka-ui.yml
version: "2"
services:
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "9050:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:9091,kafka2:9092,kafka3:9093
- KAFKA_CLUSTERS_0_ZOOKEEPER=zk1:2181,zk2:2181,zk3:2181kafka UI의 경우 카프카 클러스터의 운영 환경을 대시보드로 보여주어 운영에 편리함을 가져다준다.
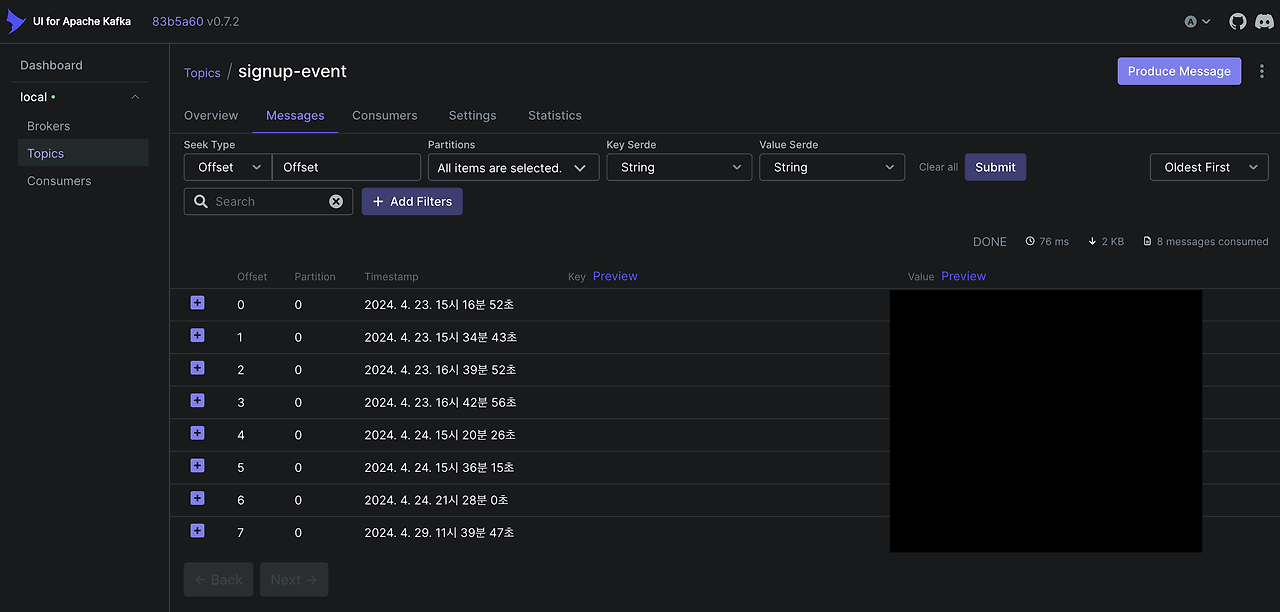
브로커가 살았는지 죽었는지, 토픽들은 어떤 것들이 생성됐는지, 메시지는 어떤 것들이 오고 가는지 한 눈에 볼 수 있어 편리하다.
Kafka Topic Management with Spring
Kafka Topic의 관리를 보통 CLI로 직접 하곤 한다. 하지만 이는 IaC 의 관점에서 코드를 git으로 관리할 수 없어 추천하지 않는다.
이를 Spring 프로젝트로 분리해서 관리하면, 실제 프로덕트 환경에서는 CI/CD를 통해 VPC 내부에서 토픽 생성/삭제를, 개발 환경에서는 직접 클러스터에 접속해 토픽을 코드로서 관리할 수 있다.
KafkaConfig.class
@EnableKafka
@Configuration
public class KafkaConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean public NewTopic SignupEvent() {
return new NewTopic("signup-event", 3, (short) 2);
}
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String,Object> configs = new HashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configs);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> configs = new HashMap<>();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, "suite");
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(configs, new StringDeserializer(), new StringDeserializer());
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}Topic 부분
@Bean public NewTopic SignupEvent() {
return new NewTopic("signup-event", 3, (short) 2);
}method 빈 등록을 통해 토픽을 관리할 수 있다.
application.yml
spring:
kafka:
bootstrap-servers: kafka-service-test-0:9092,kafka-service-test-1:9092,kafka-service-test-2:9092,kafka-service-test-3:9092
server:
port: 9010Kafka Cluster Producer / Consumer
Producer
kafka config와 yml은 동일하다. 프로듀스 하는 부분을 살펴보자
@Service
@Slf4j
@RequiredArgsConstructor
public class MemberInfoProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
@Value("${topic.SIGNUP-EVENT}")
private String SIGNUP_EVENT;
public void memberInfoProducer(Map<String, Object> data) {
log.info("signup-event message: {}", data);
this.kafkaTemplate.send(SIGNUP_EVENT, makeMessage(data));
}
private String makeMessage(Map<String, Object> data) {
JSONObject obj = new JSONObject();
obj.put("uuid", "MemberInfoProducer/" + Instant.now().toEpochMilli());
obj.put("data", data);
return obj.toJSONString();
}
}빈등록을 했던 kafkaTemplate을 사용해 프로듀싱을 진행한다.
이때 데이터는 Json으로 만들어진 String이여야 하며 직렬화 과정이 필요하다.
Consumer
@Service
@Slf4j
@RequiredArgsConstructor
public class SuiteRoomConsumer {
private final SuiteRoomRepository suiteRoomRepository;
private final ParticipantRepository participantRepository;
@Transactional
@KafkaListener(topics = { "${topic.SUITEROOM_JOIN}", "${topic.SUITEROOM_CANCELJOIN_ERROR}" }, groupId = "suiteRoomJoinConsumers", containerFactory = "kafkaListenerContainerFactory")
public void suiteRoomJoinConsume(ConsumerRecord<String, String> record) throws IOException, ParseException {
JSONParser parser = new JSONParser();
ObjectMapper objectMapper = new ObjectMapper();
JSONObject jsonObject = (JSONObject) parser.parse(record.value());
JSONObject data = ((JSONObject) jsonObject.get("data"));
Long suiteRoomId = Long.parseLong(data.get("suiteRoomId").toString());
boolean isHost = Boolean.parseBoolean(data.get("isHost").toString());
JSONObject authorizerDtoObject = ((JSONObject) data.get("authorizerDto"));
AuthorizerDto authorizerDto = objectMapper.readValue(authorizerDtoObject.toString(), AuthorizerDto.class);
if(isHost) updateHostStatus(suiteRoomId, authorizerDto.getMemberId());
else addParticipant(suiteRoomId, isHost, authorizerDto);
}
@Transactional
@KafkaListener(topics = "${topic.SUITEROOM_START_ERROR}", groupId = "suiteRoomStartErrorConsumers", containerFactory = "kafkaListenerDefaultContainerFactory")
public void suiteRoomStartErrorConsume(ConsumerRecord<String, String> record) throws IOException, ParseException {
JSONParser parser = new JSONParser();
JSONObject jsonObject = (JSONObject) parser.parse(record.value());
JSONObject data = ((JSONObject) jsonObject.get("data"));
Long suiteRoomId = Long.parseLong(data.get("suiteRoomId").toString());
SuiteRoom suiteRoom = suiteRoomRepository.findBySuiteRoomId(suiteRoomId).orElseThrow(() -> new CustomException(StatusCode.NOT_FOUND));
suiteRoom.startErrorSuiteRoom();
participantRepository.findBySuiteRoom_SuiteRoomId(suiteRoomId).stream().map(
p -> {
p.updateStatus(SuiteStatus.READY);
return p;
});
}
@Transactional
@KafkaListener(topics = "${topic.SUITEROOM_TERMINATE_COMPLETE}", groupId = "suiteRoomTerminateCompleteConsumers", containerFactory = "kafkaListenerDefaultContainerFactory")
public void terminateSuiteRoomCompleteConsume(ConsumerRecord<String, String> record) throws IOException, ParseException {
JSONParser parser = new JSONParser();
JSONObject jsonObject = (JSONObject) parser.parse(record.value());
JSONObject data = ((JSONObject) jsonObject.get("data"));
Long suiteRoomId = Long.parseLong(data.get("suiteRoomId").toString());
suiteRoomRepository.deleteBySuiteRoomId(suiteRoomId);
}
@Transactional
@KafkaListener(topics = "${topic.HALLOFFAME-SELECTION}", groupId = "hallOfFameSelectionConsumers", containerFactory = "kafkaListenerDefaultContainerFactory")
public void selectHallOfFame(ConsumerRecord<String, String> record) throws IOException, ParseException {
JSONParser parser = new JSONParser();
JSONObject jsonObject = (JSONObject) parser.parse(record.value());
JSONObject data = ((JSONObject) jsonObject.get("data"));
Long suiteRoomId = Long.parseLong(data.get("suiteRoomId").toString());
Double honorPoint = Double.valueOf(data.get("honorPoint").toString());
SuiteRoom suiteRoom = suiteRoomRepository.findBySuiteRoomId(suiteRoomId).orElseThrow(() -> new CustomException(StatusCode.NOT_FOUND));
suiteRoom.setHonorPoint(honorPoint);
}
private void addParticipant(Long suiteRoomId, boolean isHost, AuthorizerDto authorizerDto) {
SuiteRoom suiteRoom = suiteRoomRepository.findBySuiteRoomId(suiteRoomId).get();
Participant participant = Participant.builder()
.authorizerDto(authorizerDto)
.status(SuiteStatus.READY)
.isHost(isHost).build();
suiteRoom.addParticipant(participant);
participantRepository.save(participant);
}
private void updateHostStatus(Long suiteRoomId, Long memberId) {
Participant host = participantRepository.findBySuiteRoom_SuiteRoomIdAndMemberIdAndIsHost(suiteRoomId, memberId, true).get();
host.updateStatus(SuiteStatus.READY);
}
}사용하던 코드를 가져와 복잡하지만 @KafkaListener 어노테이션을 사용해 카프카 메시지 프로듀싱 이벤트를 캐치하고 데이터를 컨슈밍한다. 이후 내용은 비지니스 로직을 추가해 작업하면 된다.